42. 用functools.wraps 定义函数修饰器
1. python为修饰器提供了专门的语法,它使得程序在运行的时候,能够用一个函数来修改另一个函数
2. 对于调试器这种依赖内省机制的工具,直接编写修饰器会引发奇怪的行为
3. 内置的functools 模块提供了名为 wraps的修饰器,开发者在定义自己的修饰器时,应该用wraps对其做一些处理,避免一些问题
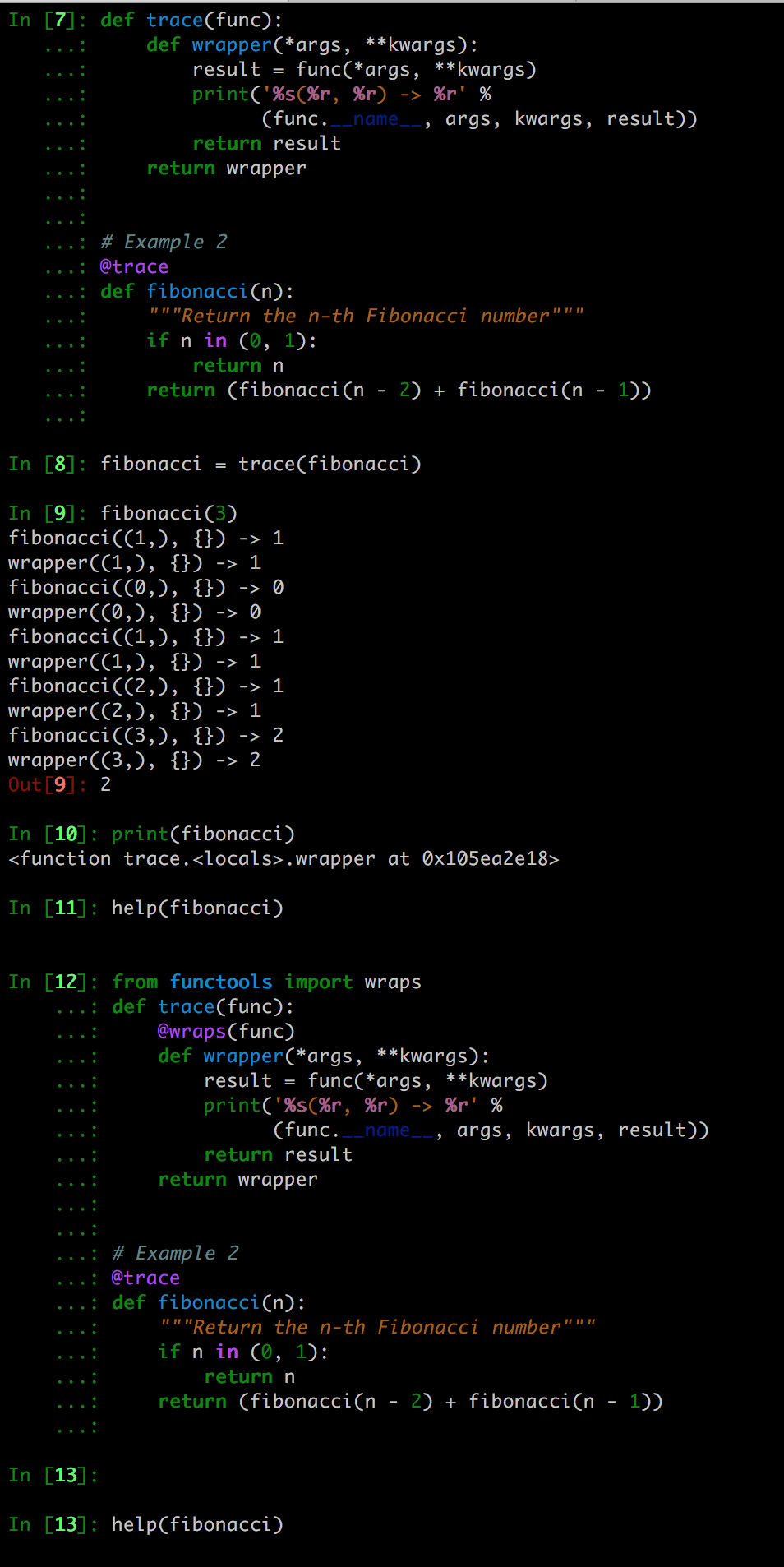
def trace(func):
def wrapper(*args, **kwargs):
result = func(*args, **kwargs):
print('%s(%r, %r) -> %r' % (func.__name__, args, kwargs, result))
return result
return wrapper
# 可以用 @ 符号把刚才那个装饰器套用到某个函数上面
# 使用 @ 符号来修饰函数,其效果就等于先以该函数为参数,调用修饰器,然后把修饰器所返回的结果,赋给同一个作用域中与原函数同名的那个变量。
# fibonacci = trace(fibonacci)
@trace
def fibonacci(n):
"""Return the n-th Fibonacci number"""
if n in (0, 1):
return n
return (fibonacci(n -2) + fibonacci(n -1))
fibonacci(3)
>>>
fibonacci((1,), {}) -> 1
fibonacci((0,), {}) -> 0
fibonacci((1,), {}) -> 1
fibonacci((2,), {}) -> 1
fibonacci((3,), {}) -> 2
如果编写修饰器的时候,没有用wraps做相应的处理,那就会令help函数失效。除了help函数,修饰器还会导致其他一些难于排查的问题。为了维护函数的接口,修饰之后的函数,必须保留原函数的某些标准python属性,例如 __name__和__module__。因此,我们需要用wraps来确保修饰后的函数具备正确的行为
43. 考虑以contextlib和with语句来改写可复用的try/finally代码
1. 可以用with语句来改写 try/finally块中的逻辑,以便提升复用程度,并使代码更加整洁
2. 内置的contextlib模块提供了名叫contextmanager的修饰器,开发者只徐亚用它来修饰自己的函数,即可令该函数支持with语句
3. 情景管理器可以通过yield语句向with语句返回一个值,此值会赋给由as关键字所指定的变量。该机制阐明了这个特殊情境的编写动机,并令with块中的语句能够直接访问这个目标变量
from threading import Lock
lock = Lock()
# 表示只有当程序持有该锁的时候,with语句块里面的那些代码,才会得到执行
# 由于Lock类对with语句提供了适当的支持,所以上面这种写法,可以达到与try/finally结构相仿的效果
with lock:
print('Lock is held')
lock.acquire()
try:
print('Lock is held')
finally:
lock.release()
使用contextlib模块中的 contextmanager 修饰器可以更加快捷的创建对with语句的支持。如果使用标准的方式,那就要定义新的类,并提供名为 __enter__和__exit__的特殊方法。
import logging
from contextlib import contextmanager
logging.getLogger().setLevel(logging.WARNING)
def my_function():
logging.debug('Some debug data')
logging.error('Error log here')
logging.debug('More debug data')
# 定义一种情景管理器,来临时提升函数的信息级别(log level)。下面这个辅助函数,会在
# 运行with块内的代码之前,临时提升信息级别,待with块执行完毕,再恢复原有级别。
@contextmanager
def debug_logging(level):
logger = logging.getLogger()
old_level = logger.getEffectiveLevel()
logger.setLevel(level)
try:
yield # 这里就是with块中的语句所要展开执行的地方。with块所抛出任何异常,都会
# 由 yield表达式从新抛出,这使得开发者可以在辅助函数里面捕获它
finally:
logger.setLevel(old_level)
with debug_logging(logging.DEBUG):
print('Inside:')
my_function()
print('After:')
my_function()
>>>
Inside:
DEBUG:Some debug data
ERROR:Error log here
DEBUG:More debug data
After:
ERROR:Error log here
使用带有目标的with语句
传给with语句的那个情境管理器,本身也可以返回一个对象。而开发者可以通过with复合语句中的as关键字,来指定一个局部变量,python会把那个对象,赋给这个局部变量。这使得with块中的代码,可以直接与外部情境相交互。
with open('/tmp/my_output.txt', 'w') as handle:
handler.write('This is some data!')
我们只需在情境管理器里,通过yield语句返回一个值,即可令自己的函数把该值提供给由as关键字所指定的目标变量。例如,下面定义的这个情境管理器,能够获取Logger实例,设置其级别,并通过yield语句将其提供给由as关键字所指定的目标
import logging
from contextlib import contextmanager
@contextmanager
def log_level(level, name):
logger = logging.getLogger(name)
old_level = logger.getEffectiveLevel()
logger.setLevel(level)
try:
yield logger
finally:
logger.setLevel(old_level)
with log_level(logging.DEBUG, 'my-log') as logger:
logger.debug('This is my message!')
logging.debug('This will not print')
# >>> Output:
# This is my message!
# python自带的那个logger,默认会处在WARNING级别,退出with语句块之后,我们在名为'my-log'的Logger上面调用debug方法,是打印不出消息的,因为该Logger的严重级别,已经恢复到默认的WARNING了。但是由于ERROR级别高于WARNING级别,所有在这个Logger上面调用 error方法,任然能够打印出消息
logger = logging.getLogger('my-log')
logger.debug('Debug will not print')
logger.error('Error will print')
>>>
Error will print
44. 用copyreg 实现可靠的pickle操作
- 内置的pickle模块,只适合用来在彼此信任的程序之间,对相关对象执行序列化和反序列化操作
- 如果用法比较复杂,那么pickle模块的功能也许就会出问题
- 我们可以把内置的copyreg 模块同 pickle结合起来使用,以便为旧数据添加缺失的属性值、进行类的版本管理,并给序列化之后的数据提供固定的引入路径
class GameState(object):
def __init__(self):
self.level = 0
self.lives = 4
state = GameState()
state.level += 1 # Player beat a level
state.lives -= 1 # Player had to try again
import pickle
state_path = 'game_state.bin'
with open(state_path, 'wb') as f:
pickle.dump(state, f)
with open(state_path, 'rb') as f:
state_after = pickle.load(f)
print(state_after.__dict__)
class GameState(object):
def __init__(self):
self.level = 0
self.lives = 4
self.points = 0
state = GameState()
serialized = pickle.dumps(state)
state_after = pickle.loads(serialized)
print(state_after.__dict__)
with open(state_path, 'rb') as f:
state_after = pickle.load(f)
print(state_after.__dict__)
assert isinstance(state_after, GameState)
class GameState(object):
def __init__(self, level=0, lives=4, points=0):
self.level = level
self.lives = lives
self.points = points
def pickle_game_state(game_state):
kwargs = game_state.__dict__
return unpickle_game_state, (kwargs,)
def unpickle_game_state(kwargs):
return GameState(**kwargs)
import copyreg
copyreg.pickle(GameState, pickle_game_state)
state = GameState()
state.points += 1000
serialized = pickle.dumps(state)
state_after = pickle.loads(serialized)
print(state_after.__dict__)
class GameState(object):
def __init__(self, level=0, lives=4, points=0, magic=5):
self.level = level
self.lives = lives
self.points = points
self.magic = magic
state_after = pickle.loads(serialized)
print(state_after.__dict__)
class GameState(object):
def __init__(self, level=0, points=0, magic=5):
self.level = level
self.points = points
self.magic = magic
try:
pickle.loads(serialized)
except:
logging.exception('Expected')
else:
assert False
def pickle_game_state(game_state):
kwargs = game_state.__dict__
kwargs['version'] = 2
return unpickle_game_state, (kwargs,)
def unpickle_game_state(kwargs):
version = kwargs.pop('version', 1)
if version == 1:
kwargs.pop('lives')
return GameState(**kwargs)
copyreg.pickle(GameState, pickle_game_state)
state_after = pickle.loads(serialized)
print(state_after.__dict__)
copyreg.dispatch_table.clear()
state = GameState()
serialized = pickle.dumps(state)
del GameState
class BetterGameState(object):
def __init__(self, level=0, points=0, magic=5):
self.level = level
self.points = points
self.magic = magic
try:
pickle.loads(serialized)
except:
logging.exception('Expected')
else:
assert False
print(serialized[:25])
copyreg.pickle(BetterGameState, pickle_game_state)
state = BetterGameState()
serialized = pickle.dumps(state)
print(serialized[:35])
45. 应该用datetime 模块来处理本地时间,而不是用time模块
- 不要用time模块在不同时区之间进行转换
- 如果要在不同时区之间,可靠地执行转换操作,那就应该把内置的datetime模块与开发者社区提供的pytz模块搭配起来使用
- 开发者总是应该先把时间表示成 UTC格式,然后对其执行各种转换操作,最后再把它转回本地时间
from time import mktime, strptime
from datetime import datetime, timezone
time_format = '%Y-%m-%d %H:%M:%S'
now = datetime(2014, 8, 10, 18, 18, 30)
now_utc = now.replace(tzinfo=timezone.utc)
now_local = now_utc.astimezone()
print(now_local)
>>>2014-08-11 02:18:30+08:00
time_str = '2014-08-10 11:18:30'
now = datetime.strptime(time_str, time_format)
time_tuple = now.timetuple()
utc_now = mktime(time_tuple)
print(utc_now)
>>>1407640710.0
# 进行协调时区转换操作
import pytz
arrival_nyc = '2014-05-01 23:33:24'
nyc_dt_naive = datetime.strptime(arrival_nyc, time_format)
eastern = pytz.timezone('US/Eastern')
nyc_dt = eastern.localize(nyc_dt_naive)
utc_dt = pytz.utc.normalize(nyc_dt.astimezone(pytz.utc))
print(utc_dt)
>>>2014-05-02 03:33:24+00:00
pacific = pytz.timezone('US/Pacific')
sf_dt = pacific.normalize(utc_dt.astimezone(pacific))
print(sf_dt)
>>>2014-05-01 20:33:24-07:00
nepal = pytz.timezone('Asia/Katmandu')
nepal_dt = nepal.normalize(utc_dt.astimezone(nepal))
print(nepal_dt)
>>>2014-05-02 09:18:24+05:45
46. 使用内置算法与数据结构
-
双向队列
collections 模块中的deque类,是一种双向队列(double-ended queue,双端队列)。从该队列的头部或尾部插入或移除一个元素,只需要消耗常数级别的时间。这一特性,使得它非常适合用来表示先进先出的队列。从list尾部插入或移除元素,也仅仅需要常数级别的时间。但是,从list头部插入或移除元素,却会耗费线性级别的时间,这与deque的常数级时间相比,要慢的多。
from collections import deque fifo = deuqe() fifo.append(1) # Producer x = fifo.popleft() # Consumer -
有序字典
标准的字典是无序的,可以使用 collections 模块中的 OrderedDict类,一种特殊的字典,它能够按照健的插入顺序,来保留键值对在字典中的次序。
from collections import OrderedDict a = OrderedDict() a['foo'] = 1 a['bar'] = 2 b = OrderedDict() b['foo'] = 'red' b['bar'] = 'blue' for value1, value2 in zip(a.values(), b.values()): print(value1, value2) >>> 1 red 2 blue -
带有默认值的字典
stats = {} key = 'my_counter' if key not in stats: stats[key] = 0 stats[key] += 1 print(stats) # 使用默认值字典代替上面的代码 from collections import defaultdict stats = defaultdict(int) stats['my_counter'] += 1 print(dict(stats)) -
堆队列(优先级队列)
堆(heap) 是一种数据结构,很适合用来实现优先级队列。heapq 模块提供了heappush、heappop和nsmallest等一些函数,能够在标准的list类型只中创建堆结构。
各种优先级的元素,都可以按任意顺序插入堆中。
from heapq import * a = [] heappush(a, 5) heappush(a, 3) heappush(a, 7) heappush(a, 4) print(heappop(a), heappop(a), heappop(a), heappop(a)) >>>3 4 5 7 a = [] heappush(a, 5) heappush(a, 3) heappush(a, 7) heappush(a, 4) assert a[0] == nsmallest(1, a)[0] == 3 print('Before:', a) a.sort() print('After: ', a) >>> Before: [3, 4, 7, 5] After: [3, 4, 5, 7] -
二分查找
在list上面使用index方法来搜索某个元素,所耗的时间会与列表的长度呈线性比例。二分搜索算法的复杂度,是对数级别的。这意味着,用bisect来搜索包含一百万个元素的列表,与用index来搜索包含14个元素的列表,所耗的时间差不多。
from timeit import timeit print(timeit( 'a.index(len(a)-1)', 'a = list(range(100))', number=1000)) >>>0.0018944389885291457 print(timeit( 'bisect_left(a, len(a)-1)', 'from bisect import bisect_left;' 'a = list(range(10**6))', number=1000)) >>>0.0007423810020554811 -
与迭代器相关的工具
内置的itertools 模块中,包含大量的函数,可以用来组合并控制迭代器。itertools 函数分为三大类
-
能够把迭代器连接起来的函数
- chain 将多个迭代器按顺序连接成一个迭代器
- cycle 无线地重复某个迭代器中的各个元素
- tee 把一个迭代器拆分成多个平行的迭代器
- zip_longest 与内置的zip函数相似,但是它可以应对长度不同的迭代器
-
能够从迭代器中过滤元素的函数
- islice 在不进行复制的前提下,根据所有来切割迭代器
- takewhile 在判定函数为True的时候,从迭代器中逐个返回元素
- dropwhile 在判定函数初次为False的地方开始,逐个返回迭代器中的元素
- filterfalse 从迭代器中逐个返回能令判定函数为False的所有元素。其效果与内置的filter函数相反
-
能够把迭代器中的元素组合起来的函数
- product 根据迭代器中的元素计算笛卡尔积,并将其返回。可以用product来改写深度嵌套的列表推导操作
- permutations 用迭代器中的元素构建长度为N的各种有序排列,并将所有排列形式返回给调用者
- combination 用迭代器中的元素构建长度为N的各种无序组合,并将所有组合形式返回给调用者
除了上述的模块,itertools模块里面还有其他一些函数及教程,如果你发现自己要编写一段非常麻烦的迭代程序,那就应该先花时间来阅读 itertools的文档,看看里面有没有现成的工具可以使用。
-
47. 在重视精度的场合,应该使用decimal
- 对于编程中可能用到的每一种数值,我们都可以拿对应的python内置类型,或内置模块中的类表示
- Decimal 类非常适合用在那种对精度要求很高,且对舍入行为要求很严格的场合,例如,涉及货币计算的场合
from decimal import Decimal
from decimal import ROUND_UP
rate = Decimal('1.45')
seconds = Decimal('222') # 3*60 + 42
cost = rate * seconds / Decimal('60')
print(cost)
>>> 5.365
rounded = cost.quantize(Decimal('0.01'), rounding=ROUND_UP)
print(rounded)
>>>5.37
rate = Decimal('0.05')
seconds = Decimal('5')
cost = rate * seconds / Decimal('60')
print(cost)
>>>0.004166666666666666666666666667
# Example 8
rounded = cost.quantize(Decimal('0.01'), rounding=ROUND_UP)
print(rounded)
>>>0.01
48. 学会安装由python开发者社区所构建的模块
- Python Package Index(PyPI) 包含了许多常用的软件包,它们都是由Python开发者社区来构建并维护的
- pip是命令行工具,可以从PyPI中安装软件包
- Pyhton3.4及后续版本,默认装有pip, <3.4版本的需要自行安装pip
- 大部分PyPI模块,都是自由软件或开源软件
继续阅读关于 python 的文章
